Unidad 1
Qué es la Inteligencia Artificial: definición y conceptos clave
Unidad 1
Qué es la Inteligencia Artificial: definición y conceptos clave
Al finalizar esta unidad, el estudiante podrá identificar la definición de Inteligencia Artificial y sus conceptos clave —datos, algoritmos, modelos y entrenamiento— en documentos y recursos introductorios, de forma que pueda reconocer y explicar estos términos cuando los encuentre en artículos, noticias o conversaciones sobre tecnología.
Cuando escuchamos hablar de Inteligencia Artificial (IA), es común imaginar robots humanoides de películas de ciencia ficción o computadoras que piensan exactamente como personas. Sin embargo, la realidad es más cercana, más útil y, al mismo tiempo, más fascinante que esa imagen.
En términos generales, la Inteligencia Artificial es el campo de la informática que se dedica a crear sistemas capaces de realizar tareas que, si las hiciera un ser humano, requerirían inteligencia. Esto incluye actividades como reconocer objetos en una fotografía, traducir texto de un idioma a otro, recomendar una canción según tus gustos o detectar un fraude bancario en fracciones de segundo.
Una de las definiciones más citadas proviene de John McCarthy, uno de los pioneros del campo, quien en 1956 describió la IA como «la ciencia e ingeniería de hacer máquinas inteligentes». Décadas después, el investigador Stuart Russell y su colega Peter Norvig ampliaron esta visión en su obra de referencia Artificial Intelligence: A Modern Approach, describiendo la IA como el estudio de agentes que perciben su entorno y toman acciones para maximizar sus probabilidades de éxito.
Lo que hace especialmente relevante a la IA hoy en día es su capacidad para aprender de los datos. A diferencia de los programas tradicionales, que siguen instrucciones fijas escritas por programadores, los sistemas de IA modernos pueden mejorar su desempeño con la experiencia, ajustando su comportamiento a medida que procesan más información.
Para comprender qué hace la IA y qué no, es útil comparar cómo aprende un ser humano con cómo lo hace una máquina.
Cuando un niño aprende a distinguir un perro de un gato, no recibe un manual con reglas como «si tiene hocico largo, es perro». En cambio, ve cientos de ejemplos —en la calle, en libros, en televisión— y su cerebro construye, de forma inconsciente, un patrón que le permite reconocer animales nuevos con gran precisión. La IA moderna funciona de manera análoga: en lugar de programar reglas explícitas, se le muestran miles o millones de ejemplos y el sistema aprende los patrones por sí solo.
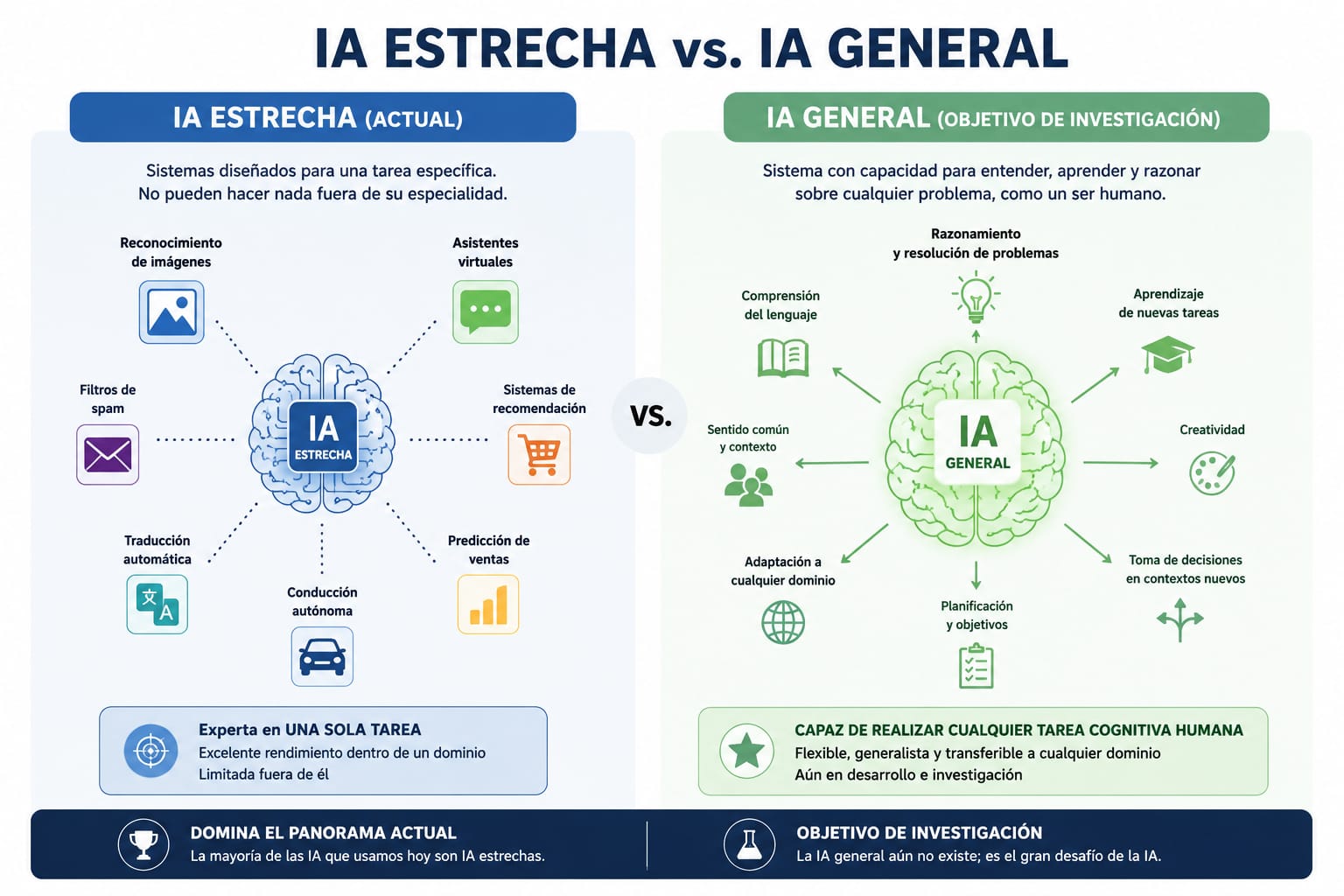
Sin embargo, la comparación tiene límites importantes. La inteligencia humana es general: podemos aprender una habilidad nueva sin olvidar las anteriores, transferir conocimiento entre dominios y razonar en situaciones completamente inéditas. La IA actual, en cambio, es predominantemente estrecha (narrow AI): un sistema entrenado para reconocer imágenes médicas no sabe jugar ajedrez, y un modelo que traduce textos no puede conducir un automóvil.
Esta distinción entre IA estrecha e IA general (también llamada AGI, Artificial General Intelligence) es fundamental para entender los alcances y las limitaciones reales de la tecnología. En la práctica, absolutamente todo lo que usamos hoy —asistentes de voz, motores de búsqueda, filtros de spam— es IA estrecha especializada en una tarea concreta.
Si la IA fuera una fábrica, los datos serían su materia prima. Sin datos, no hay aprendizaje posible. Pero ¿qué son exactamente los datos en el contexto de la IA?
Los datos son cualquier conjunto de información estructurada o no estructurada que puede ser procesada por una computadora. Pueden ser números, textos, imágenes, audios, videos, registros de transacciones o incluso señales de sensores. Lo que los hace valiosos para la IA es que contienen patrones ocultos que los sistemas pueden aprender a reconocer.
Pensemos en un ejemplo cotidiano: un servicio de streaming como Netflix recopila datos sobre qué películas viste, cuánto tiempo las viste, en qué momento las pausaste y qué calificación les diste. Con millones de usuarios generando ese tipo de información, el sistema puede identificar patrones como «los usuarios que disfrutaron A y B también suelen disfrutar C» y hacer recomendaciones sorprendentemente precisas.
Es importante entender que la cantidad y la calidad de los datos importan enormemente. Un sistema entrenado con pocos datos o con datos sesgados —por ejemplo, fotos de personas de un solo grupo étnico para entrenar un reconocedor facial— producirá resultados deficientes o injustos. En unidades posteriores explorarás con más detalle las implicaciones de esto.
Un algoritmo es, en esencia, un conjunto de instrucciones paso a paso que una computadora sigue para resolver un problema o completar una tarea. El término puede sonar técnico, pero usamos algoritmos en la vida cotidiana sin darnos cuenta: una receta de cocina es un algoritmo, al igual que las instrucciones de armado de un mueble.
En el contexto de la IA, los algoritmos de aprendizaje son los métodos matemáticos que permiten a un sistema extraer patrones de los datos. Diferentes algoritmos son adecuados para diferentes tipos de problemas. Por ejemplo:
Lo que hace especiales a los algoritmos de IA modernos es que no necesitan que un programador les diga explícitamente cuáles son las reglas. En cambio, descubren las reglas por sí mismos a partir de los ejemplos. Esta capacidad es lo que hace a la IA tan poderosa y, al mismo tiempo, tan difícil de explicar cuando toma una decisión.
Cuando un algoritmo de IA procesa datos, el resultado de ese proceso es lo que llamamos un modelo. Un modelo es una representación matemática de los patrones que el sistema encontró en los datos de entrenamiento. Es, en cierta forma, el "conocimiento" que la IA adquirió.
Piénsalo así: si el algoritmo es el proceso de estudiar miles de fotos de gatos y perros, el modelo es la "imagen mental" resultante que permite al sistema decidir si una foto nueva muestra un gato o un perro. El modelo no guarda todas las fotos que vio; guarda los patrones que extrajo de ellas.
Los modelos pueden ser más o menos complejos. Un modelo simple podría ser una ecuación con unos pocos parámetros. Los modelos de IA más avanzados de la actualidad, como los que impulsan asistentes de conversación, contienen miles de millones de parámetros —valores numéricos ajustados durante el entrenamiento— que capturan patrones extremadamente sutiles del lenguaje humano.
Una característica importante de los modelos es que, una vez creados, pueden aplicarse a datos nuevos que nunca vieron durante el entrenamiento. A esta capacidad se le llama generalización: el modelo no solo memoriza los ejemplos del pasado, sino que aprende reglas lo suficientemente generales como para funcionar con información nueva.
| Concepto | Definición sencilla | Analogía cotidiana | Ejemplo en IA |
|---|---|---|---|
| Datos | Información en bruto que alimenta al sistema | Los ingredientes de una receta | Millones de correos etiquetados como spam o no spam |
| Algoritmo | Conjunto de instrucciones matemáticas para aprender | La receta o el método de cocción | Regresión logística, árbol de decisión, red neuronal |
| Modelo | Resultado del aprendizaje; representación de los patrones encontrados | El platillo terminado listo para servir | El detector de spam ya entrenado que clasifica nuevos correos |
| Entrenamiento | Proceso mediante el cual el algoritmo ajusta el modelo con los datos | El tiempo de práctica que necesita un chef para perfeccionar la receta | Pasar 10 millones de imágenes a una red neuronal para que aprenda a reconocer objetos |
El entrenamiento es el proceso central del aprendizaje automático. Durante el entrenamiento, el algoritmo recibe los datos de entrada, hace una predicción, compara esa predicción con la respuesta correcta, mide el error y ajusta los parámetros del modelo para reducirlo. Este ciclo se repite miles o millones de veces hasta que el modelo alcanza un nivel de precisión aceptable.
Para ilustrar esto, imagina que estás aprendiendo a calcular propinas en un restaurante. La primera vez que lo intentas, probablemente tu cálculo sea impreciso. Pero con la práctica —cada vez comparas tu cálculo con el correcto y ajustas tu método— vas mejorando. El entrenamiento de una IA funciona de manera muy parecida, solo que a una velocidad y escala incomparablemente mayores.
El entrenamiento requiere tres elementos esenciales:
Datos de entrenamiento: el conjunto de ejemplos con los que el sistema aprende. Generalmente están etiquetados, es decir, cada ejemplo incluye la respuesta correcta (por ejemplo, una foto de un gato con la etiqueta «gato»).
Una función de pérdida (loss function): una medida matemática del error del modelo. Cuanto más baja sea esta medida, mejor es el modelo.
Un optimizador: el mecanismo que ajusta los parámetros del modelo para reducir la función de pérdida en cada iteración.
Es importante destacar que el entrenamiento es costoso en recursos: requiere grandes cantidades de datos, potencia computacional y tiempo. Entrenar un modelo avanzado de lenguaje puede consumir tanta electricidad como cientos de hogares durante meses. Este costo tiene implicaciones ambientales y económicas que son objeto creciente de debate en la comunidad tecnológica.
Se identifica qué tarea debe resolver la IA (por ejemplo, detectar correo no deseado). Se determina qué tipo de datos se necesitan y cuál es el criterio de éxito.
Se reúnen los datos relevantes (correos electrónicos, en nuestro ejemplo), se limpian (eliminando duplicados o errores) y se etiquetan (cada correo se marca como spam o legítimo).
Los ingenieros eligen el tipo de algoritmo más adecuado para el problema y los datos disponibles. Esta elección depende de la cantidad de datos, el tipo de tarea y los recursos computacionales disponibles.
El algoritmo procesa los datos repetidamente, ajustando los parámetros internos del modelo para minimizar el error en sus predicciones. Este paso puede durar horas, días o semanas.
El modelo se prueba con datos nuevos que no usó en el entrenamiento para medir su capacidad de generalización. Si no rinde lo esperado, se ajustan parámetros o se incorporan más datos.
El modelo validado se integra en un sistema real —una aplicación, un sitio web, un dispositivo— donde comienza a tomar decisiones o hacer predicciones sobre datos reales.
El desempeño del modelo se vigila continuamente. Si los datos del mundo real cambian con el tiempo (lo que se llama deriva de datos), el modelo debe reentrenarse con información actualizada.
Existe una clasificación ampliamente usada que organiza la IA según su nivel de capacidad cognitiva:
IA Estrecha (Narrow AI): Es la única forma de IA que existe hoy en la práctica. Cada sistema está diseñado para una tarea específica y no puede transferir ese conocimiento a otras áreas. El reconocedor de voz de tu teléfono, el algoritmo de recomendación de YouTube y el sistema de detección de fraudes de tu banco son todos ejemplos de IA estrecha.
IA General (AGI - Artificial General Intelligence): Es un tipo hipotético de IA que tendría la capacidad de razonar, aprender y adaptarse a cualquier tarea cognitiva con la misma eficiencia que un ser humano. No existe aún, y los expertos debaten activamente si —y cuándo— podría desarrollarse.
Superinteligencia Artificial: Concepto teórico que describe una IA que superaría ampliamente las capacidades cognitivas humanas en todos los aspectos. Es objeto de debate filosófico y ético, pero está completamente fuera del alcance tecnológico actual.
Comprender estas distinciones es esencial para evaluar críticamente las noticias sobre IA. Muchas veces, los medios de comunicación atribuyen capacidades de IA general a sistemas que en realidad son IA estrecha muy bien diseñada. Un chatbot que mantiene una conversación fluida no «piensa» ni «comprende» en el sentido humano; ejecuta patrones estadísticos muy sofisticados aprendidos de enormes cantidades de texto.
Especializada en una sola tarea. Ejemplos: reconocimiento facial, traducción automática, detección de fraudes, recomendación de contenido. Alta eficiencia dentro de su dominio. No puede transferir conocimiento a otras áreas. Todos los sistemas de IA actuales son de este tipo.
Capaz de aprender y razonar sobre cualquier tarea. Comparable a la inteligencia humana en amplitud y flexibilidad. Puede transferir conocimiento entre dominios distintos. No existe aún; es un objetivo de investigación a largo plazo. Su desarrollo plantea preguntas éticas profundas.
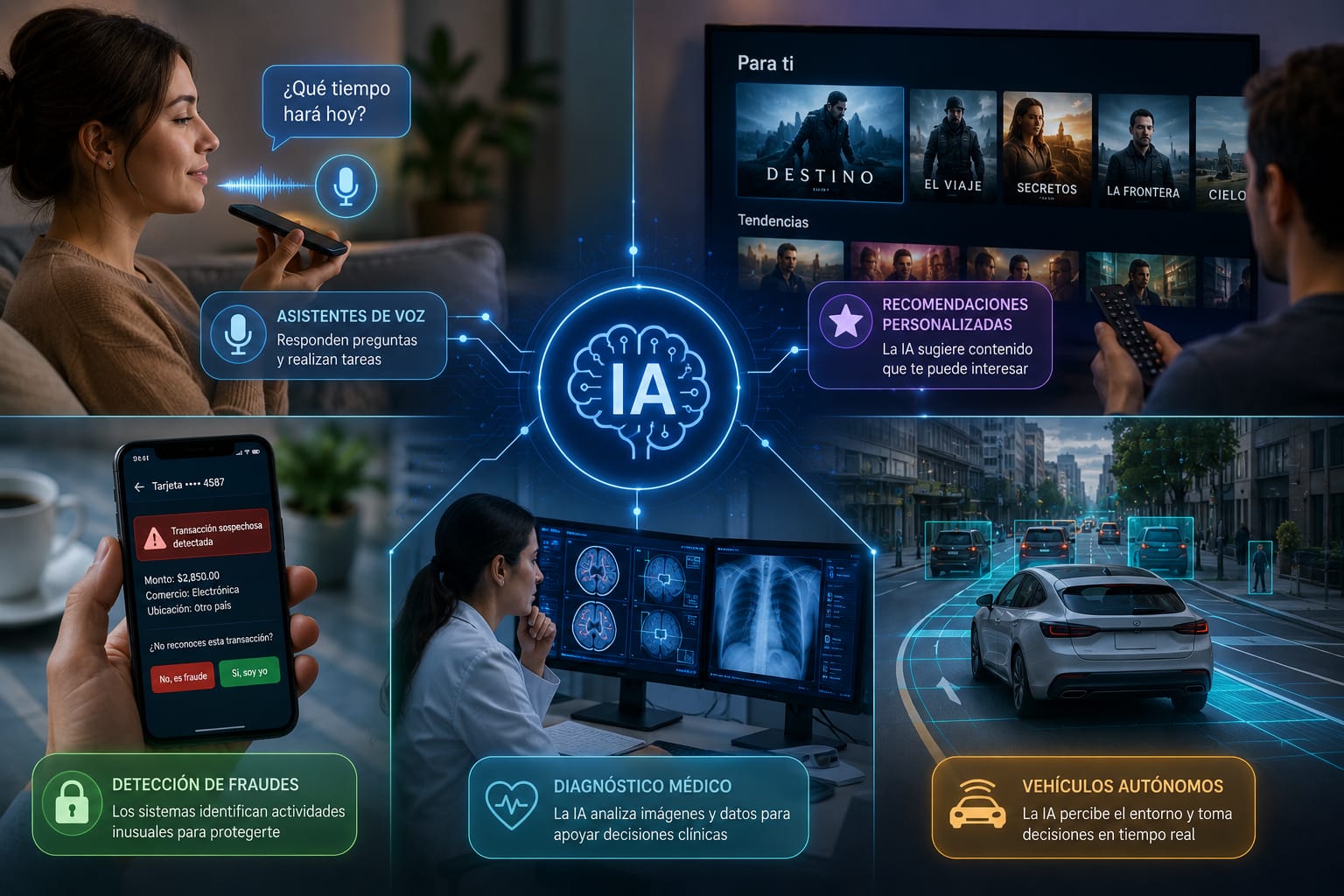
Uno de los malentendidos más comunes sobre la IA es pensar que es una tecnología del futuro o algo reservado para empresas tecnológicas gigantes. La realidad es que la IA ya forma parte de tu vida diaria de maneras que quizás no habías notado.
Cuando escribes en tu teléfono y el teclado sugiere la siguiente palabra, hay un modelo de lenguaje funcionando. Cuando tu correo electrónico detecta automáticamente que un mensaje es spam, hay un clasificador entrenado en acción. Cuando buscas algo en internet y los resultados parecen leer tu mente, hay algoritmos de relevancia y personalización operando. Cuando escuchas música en una plataforma de streaming y el siguiente artista que te sugiere resulta ser exactamente de tu gusto, hay un sistema de recomendación colaborativa trabajando en segundo plano.
En el sector salud, la IA ya ayuda a radiólogos a detectar tumores en imágenes médicas con precisión comparable a la de especialistas humanos. En el sector financiero, protege tus transacciones analizando patrones de comportamiento en tiempo real. En la industria automotriz, habilita sistemas de asistencia al conductor que salvan vidas.
Entender estos ejemplos no solo hace más concreto el concepto de IA; también te prepara para reconocer, evaluar y tomar decisiones informadas sobre la tecnología que ya usas. En las unidades siguientes profundizarás en cómo funcionan internamente estos sistemas y qué ramas del conocimiento los hacen posibles.
Es fundamental distinguir entre lo que la IA puede hacer hoy y lo que los medios o el cine proyectan sobre ella. Los sistemas de IA actuales son herramientas matemáticas muy potentes, pero no tienen conciencia, emociones ni voluntad propia. Reconocer esta diferencia te ayudará a evaluar con criterio las promesas y los riesgos reales de la tecnología.
La Inteligencia Artificial es el campo que crea sistemas capaces de realizar tareas que requerirían inteligencia si las hiciera un humano.
Los cuatro conceptos clave son: datos (materia prima), algoritmos (instrucciones de aprendizaje), modelos (resultado del aprendizaje) y entrenamiento (proceso de ajuste).
La IA actual es predominantemente estrecha: cada sistema es experto en una sola tarea y no puede generalizar a otras.
El entrenamiento consiste en un ciclo de predicción, medición del error y ajuste de parámetros, repetido miles de veces.
La IA ya está presente en tu vida cotidiana: teclados predictivos, filtros de spam, recomendaciones de contenido y detección de fraudes son ejemplos concretos.
La IA General (AGI) es un objetivo de investigación que no existe aún en la práctica.
Ahora que has construido una base sólida sobre qué es la IA y cuáles son sus conceptos fundamentales, estás listo para explorar cómo llegamos hasta aquí. La Inteligencia Artificial no nació de la noche a la mañana: es el resultado de décadas de investigación, fracasos, reactivaciones y avances extraordinarios. En la próxima unidad recorrerás esa historia, desde las primeras ideas de Alan Turing en los años cuarenta hasta los impresionantes modelos generativos que hoy capturan la atención del mundo, comprendiendo así por qué el campo se encuentra en el momento de efervescencia que vivimos actualmente.
Russell, S., & Norvig, P. (2020). Artificial intelligence: A modern approach (4th ed.). Pearson. https://aima.cs.berkeley.edu/
Mitchell, M. (2019). Artificial intelligence: A guide for thinking humans. Farrar, Straus and Giroux. https://melaniemitchell.me/aibook/
Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep learning. MIT Press. https://www.deeplearningbook.org/